Tabletop Suture Pad
Sample online rollouts of the monocular version of the GR00T N1 policy (NVIDIA et al., 2025).
*Equal contribution
Online evaluation of surgical robot policies in Cosmos-Surg-dVRK simulation.
We propose a framework for automated policy evaluation using Cosmos-Surg-dVRK, a Cosmos world foundation model (WFM) finetune, to perform simulated surgical policy rollouts and subsequent automated success rate evaluation using a video classifier.
The rise of surgical robots and vision-language-action models has accelerated the development of autonomous surgical policies and efficient assessment strategies. However, evaluating these policies directly on physical robotic platforms such as the da Vinci Research Kit (dVRK) remains hindered by high costs, time demands, reproducibility challenges, and variability in execution.
World foundation models (WFM) for physical AI offer a transformative approach to simulate complex real-world surgical tasks, such as soft tissue deformation, with high fidelity. This work introduces Cosmos-Surg-dVRK, a surgical finetune of the Cosmos WFM, which, together with a trained video classifier, enables fully automated online evaluation and benchmarking of surgical policies.
We evaluate Cosmos-Surg-dVRK using two distinct surgical datasets. On tabletop suture pad tasks, the automated pipeline achieves strong correlation between online rollouts in Cosmos-Surg-dVRK and policy outcomes on the real dVRK Si platform, as well as good agreement between human labelers and the V-JEPA 2-derived video classifier. Additionally, preliminary experiments with ex-vivo porcine cholecystectomy tasks in Cosmos-Surg-dVRK demonstrate promising alignment with real-world evaluations, highlighting the platform's potential for more complex surgical procedures.
Given a collection of multi-task surgical policies, represented either by distinct models or by different training regimes, this study aims to benchmark their success rate via online rollouts in simulation, thereby eliminating the need for immediate evaluation on a physical robot platform. The objective is to identify the policy exhibiting the highest simulated performance prior to deployment on the physical robot. To assess the validity of the Cosmos-Surg-dVRK simulation framework, a set of policies are trained first and then evaluated on the dVRK Si platform, recording both the robot’s initial state (captured as the first video frame) and the observed success or failure for each policy rollout. Subsequently, these same policies are rolled out online in the Cosmos-Surg-dVRK environment, using the recorded initial states from the dVRK Si as standardized starting conditions. The success rates attained in both the simulation and physical settings are then compared through statistical analysis to determine the fidelity of the simulation framework in replicating real-world performance.
While Cosmos-Surg-dVRK generates complete videos for each policy rollout, facilitating manual evaluation, reviewing hundreds of videos remains a time-consuming process, particularly when distinguishing subtle decision boundaries between success and failure. As such, we utilize V-JEPA 2 (Assran et al., 2025) for its strong pretrained video features and train an attentive probe classifier to automatically label success and failure events on our Cosmos-Surg-dVRK rollouts. We train a single classifier for all tabletop tasks using a frozen V-JEPA 2 ViT-H backbone on a manually collected dataset of 2,310 video clips. To accommodate V-JEPA 2’s limited context window, we process each rollout in overlapping video chunks. Then, the complete rollout is labeled as a success or failure based on whichever of those outcomes appears first.
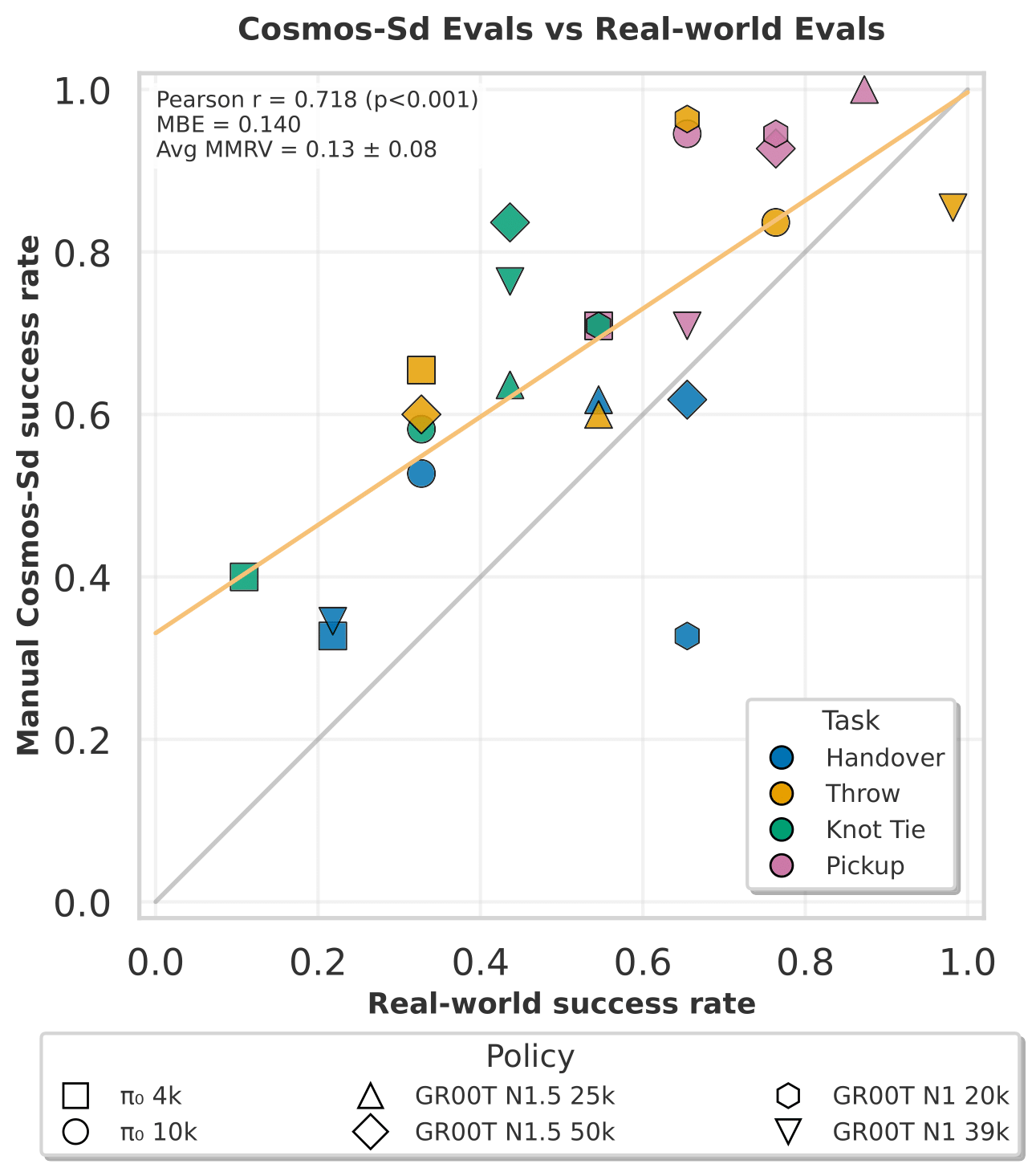
We conduct a series of experiments using Cosmos-Surg-dVRK to assess its validity as a surrogate for the real dVRK Si robotic platform. Our central hypothesis is that policy evaluations performed in simulation can reliably serve as linear predictors of corresponding real-world policy performance.
All datasets were recorded at 30Hz on a single dVRK Si system across multiple sessions and expert operators. The dVRK Si movements were recorded as multi-view video, including endoscope and wrist-camera views, as well as the time-synchronized kinematic sequences. The tabletop suture pad dataset (Haworth et al., 2025) contains four surgical tasks and encompasses 3,036 episodes with a duration of ∼13 hours. The porcine cholecystectomy dataset (Kim et al., 2025) contains 17 sub-tasks and includes 16,506 episodes with a duration of ∼18 hours. For pre-processing, we drop redundant consecutive video frames and respective kinematics.
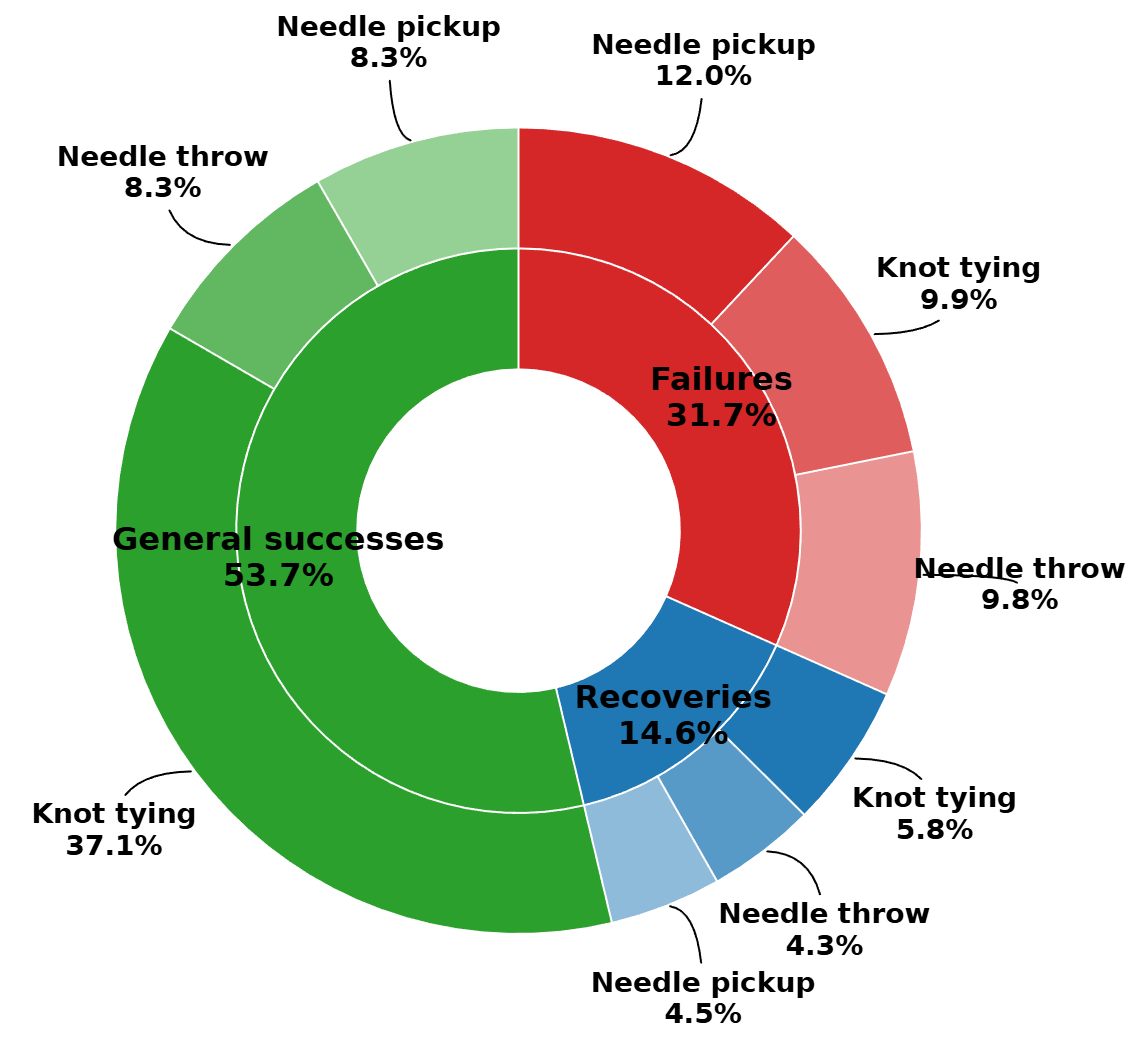
We train three different monocular VLAs (policies), π0, GR00T N1, and GR00T N1.5, on the dVRK tabletop dataset. For each policy, we evaluate two training regimes, one half training and one full training, using a) Cosmos-Surg-dVRK simulation and b) the real dVRK Si. For each policy checkpoint and environment, the success rate for each surgical task is calculated. The surgical tasks are needle pickup, needle handover, needle throw, and knot tying. Each policy is rolled out in both environments ten times per task (ten trials), each time with a different initial robot state. For each dVRK rollout, a multi-view video with paired kinematics is recorded. The corresponding Cosmos- Surg-dVRK rollout is initialized with the first endoscopic video frame from the dVRK Si recording.
Manual evaluation of policy rollouts: The success rates are determined manually both for the dVRK and the Cosmos-Surg-dVRK generated videos. For the generated videos, two raters each label three Cosmos-Surg-dVRK seeds and their averaged scores are collected as the final success rate.
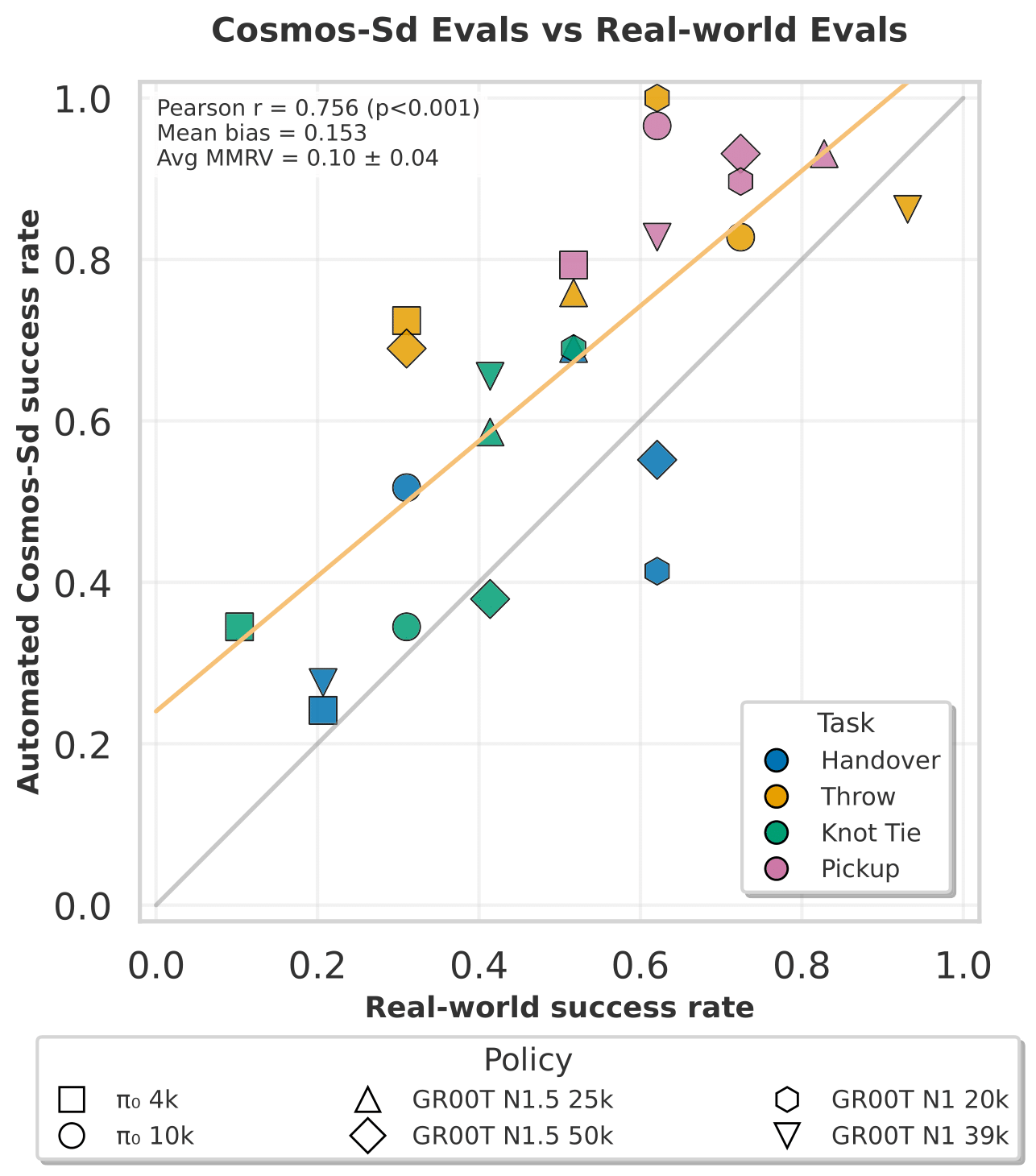
Automated evaluation of policy rollouts: We generate the V-JEPA 2 classifier labels by running inference on the same set of Cosmos-Surg-dVRK policy rollout videos used in the manual evaluation. For our final V-JEPA 2 evaluations, we average results for each policy-task combination across three generated seeds, following the same procedure as with the human labeling.
Qualitative examples are shown in section Example policy rollouts in Cosmos-Surg-dVRK.
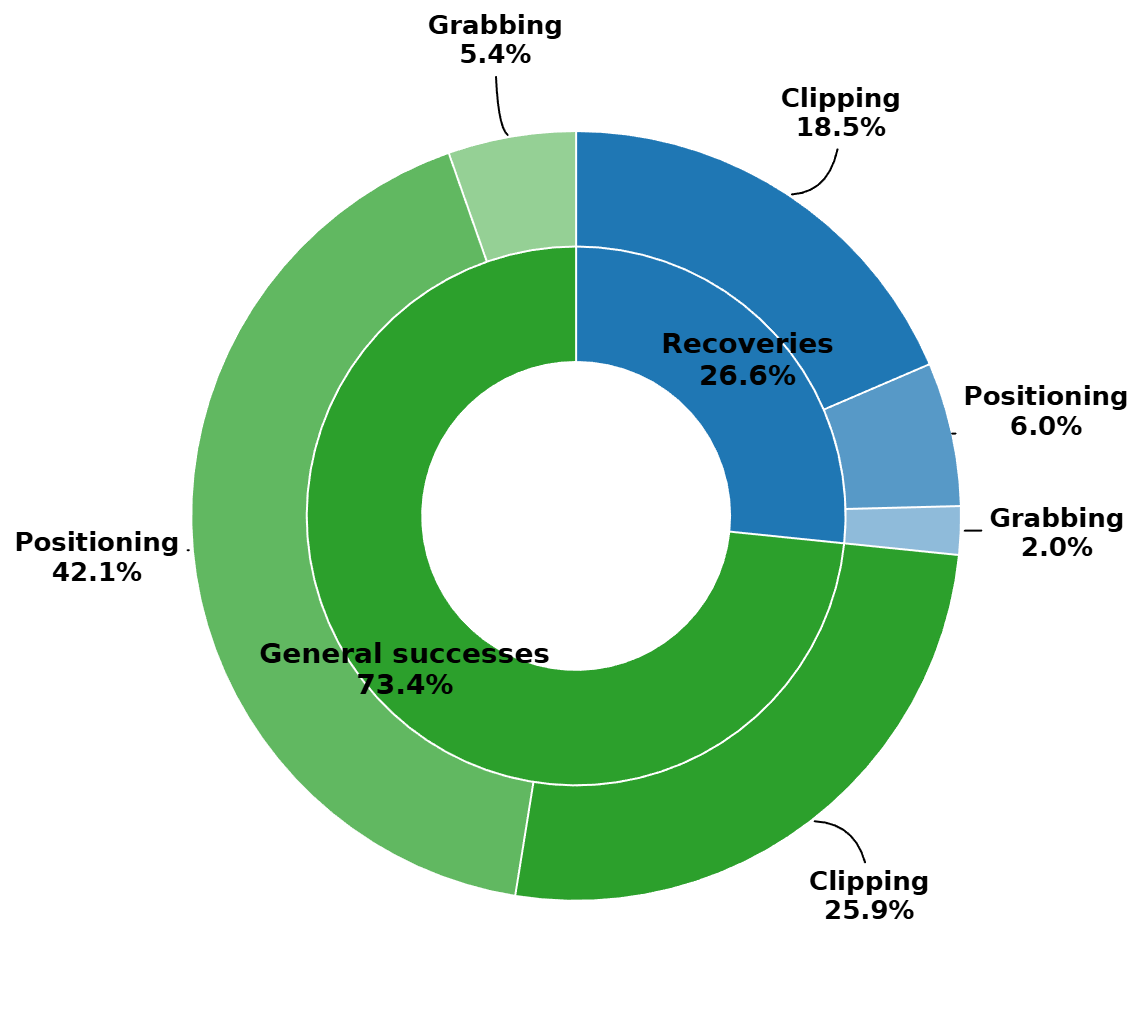
Using the monocular version of the SRT-H policy (Kim et al., 2025), we compare its performance in Cosmos-Surg-dVRK simulation with the real dVRK. The holdout test set has nine different porcine tissues and three tasks are performed, “apply first clip”, “apply third clip”, and “cut the cystic duct”. Each task has three trials, and as a consequence, we report majority-vote outcomes to ensure robustness to outlier judgments. This contrasts with the tabletop experiments, where the ten real-world trials enable us to report the average success rate, as the tabletop experiments’ larger sample size allows stable statistical estimation. Thus, for the cholecystectomy experiments, each trial is rolled out three times using different seeds for Cosmos-Surg-dVRK. The generated videos are manually rated by two raters. Each trial is counted as a success if more than 50% of the six labels are successful. A physics anomaly is counted as a failure only if it occurs as a proxy for poor policy action.
The exploratory results are summarized in Table 1. We obtain an almost identical success rate overlap across nine trials. The causes of failure in the third rollout of the task “apply third clip” using Cosmos-Surg-dVRK include the scissor missing the duct or grabbing and cutting the wrong tube.
Qualitative examples are shown in section Example policy rollouts in Cosmos-Surg-dVRK.
| System | Apply first clip | Apply third clip | Cut cystic duct | Total |
|---|---|---|---|---|
| dVRK (real-world) | 3 / 3 | 2 / 3 | 2 / 3 | 7 / 9 |
| Cosmos-Surg-dVRK | 3 / 3 | 3 / 3 | 2 / 3 | 8 / 9 |
Table 1: SRT-H policy success rates on three cholecystectomy tasks.
Initially, we finetune Cosmos-Surg-dVRK on datasets containing only successful trajectories. Qualitatively, these models show a strong positive bias, often hallucinating false positives. We therefore hypothesize that including negative examples could mitigate this bias. To test this, we collect additional trajectories resulting in task failure and subsequently train two model variants on the tabletop surgical tasks: an ablated model on successes only, and a full model on both successes and failures.
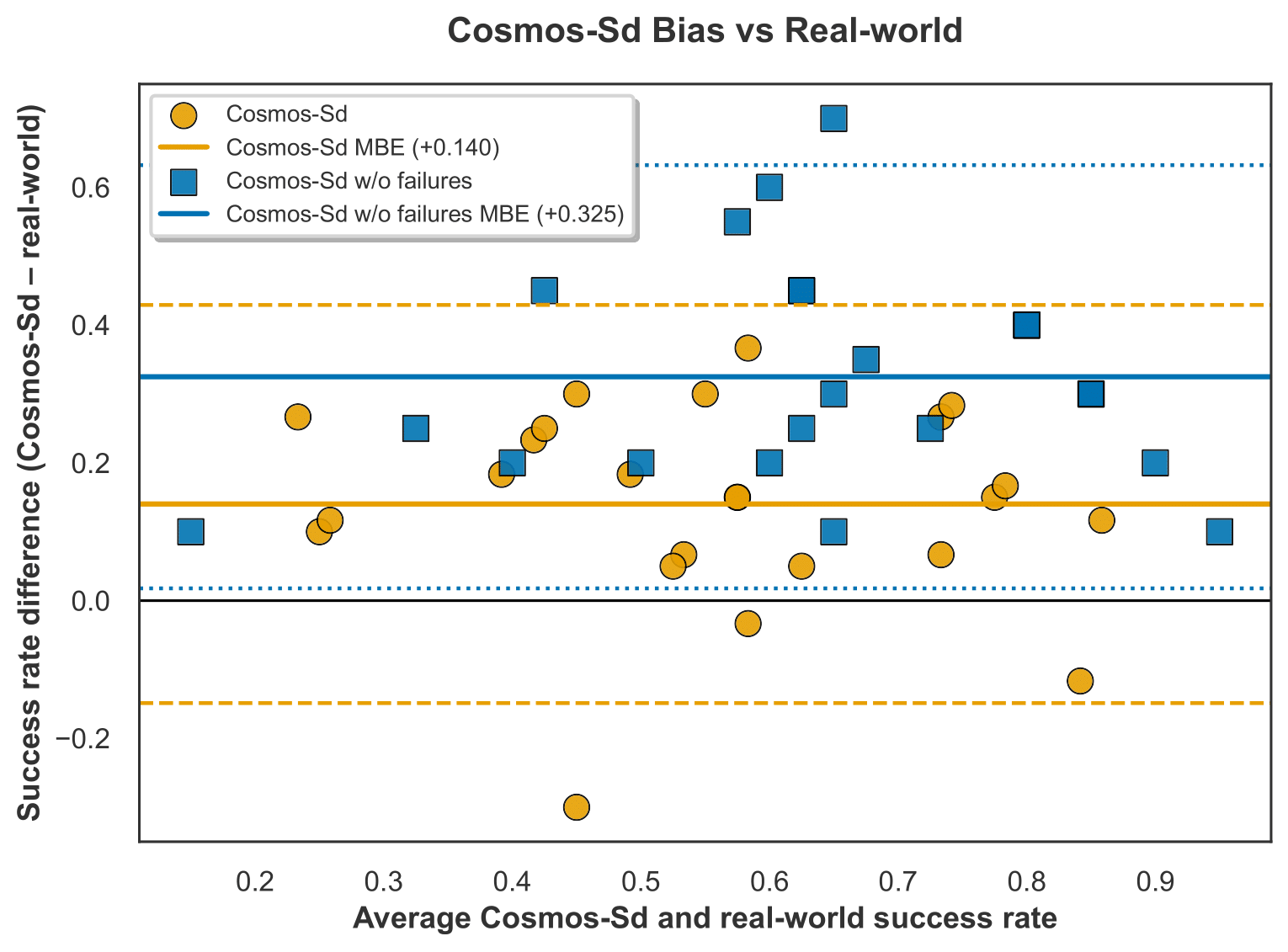
Evaluations between these two finetunes are performed on holdout data unseen by both models. For each task and policy, two raters independently label 10 unique rollouts generated from a single seed, with the final success rate being the average of their assessments. Across all tasks and metrics, the ablated Cosmos-Surg-dVRK without failure episodes yields lower performance. The figure below visualizes the positive shift in higher success rates between the Cosmos-Surg-dVRK without failure episodes version and the full Cosmos-Surg-dVRK full version. The ablated Cosmos- Surg-dVRK model exhibits a markedly larger positive mean bias error, and limits of agreement that are shifted upward compared to the full Cosmos-Surg-dVRK model.
Our findings suggest that failure episodes represent a critical factor in surgical datasets for effective world model finetuning in surgical simulation.
Sample online rollouts of the monocular version of the GR00T N1 policy (NVIDIA et al., 2025).
Knot Tie
Pickup And Handover
Throw And Extraction
Sample online rollouts of the monocular version of the SRT-H policy (Kim et al., 2025).
Apply First Clip
Apply Third Clip
Cut Cystic Duct
Sample handcrafted trajectory rollouts unseen during training ("wild kinematics").
Left Arm ⬅️ x252
(Pull gallbladder to the left)
Right Arm ⬅️ x252
(Push cystic duct to the left)
Right Arm ↗️ x252
(Push right arm into the liver)
@misc{zbinden2025cosmossurgdvrk,
title={Cosmos-Surg-dVRK: World Foundation Model-based Automated Online Evaluation of Surgical Robot Policy Learning},
author={Lukas Zbinden and Nigel Nelson and Juo-Tung Chen and Xinhao Chen and Ji Woong Kim and Mahdi Azizian and Axel Krieger and Sean Huver},
year={2025},
eprint={2510.16240},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2510.16240},
}
For any questions, please feel free to contact Lukas Zbinden and Nigel Nelson.